简介
本文旨在介绍 Python 全局解释器锁(GIL)的问题,详细讨论其影响,并探索利用多线程、多进程和协程处理并发任务的不同策略。我们还将提供实际的代码示例,以帮助读者理解和应用这些概念。
什么是Python GIL
Python 全局解释器锁(GIL),是 Python 解释器设计的一个重要部分。由于历史原因和设计选择,Python 的内存管理不是线程安全的。为了避免在处理多线程时出现冲突,Python 解释器采用了一个全局解释器锁。这意味着在任何时间点,只能有一个线程在 Python 解释器中执行字节码。即使在多核处理器的环境下,Python 也无法利用多个处理器来并行执行多线程代码。
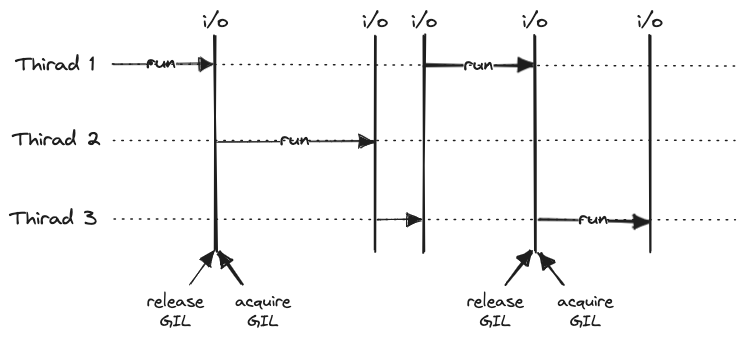
Python GIL的影响
GIL 的存在意味着,即使在具有多个核心的系统上,Python 的多线程代码也无法同时使用多个核心。这对于 CPU 密集型的多线程程序(如计算或模拟)造成了严重的性能问题,因为这些程序不能充分利用现代多核处理器的性能。
然而,对于 I/O 密集型的多线程程序(如网络或磁盘 I/O),GIL 的影响就较小了。这是因为在等待 I/O 操作完成的过程中,线程会释放GIL,从而充许其他线程运行。
下面是一个简单的多线程示例,说明了 GIL 的影响:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
import threading
import time
def cpu_bound_task():
# CPU密集型任务
count = 0
for i in range(10**8):
count += i
start = time.time()
threads = []
for _ in range(2):
thread = threading.Thread(target=cpu_bound_task)
thread.start()
threads.append(thread)
for thread in threads:
thread.join()
end = time.time()
print(f"Execution time: {end - start} seconds")
在这个例子中,我们创建了两个线程,每个线程执行一个 CPU 密集型任务。你会发现,这个程序的执行时间几乎等于两个任务单独执行的时间之和,而不是它们并行执行的时间。这是因为GIL阻止了线程的并行执行。
如何有效利用多核处理器
尽管 Python 的 GIL 限制了多线程的并行执行,但我们仍有方法绕过这个问题,充分利用多核处理器。以下是其中的几种方法:
- 多进程:每个 Python 进程都有自己的 Python 解释器和 GIL,因此多进程可以在多核处理器上并行执行。Python的
multiprocessing模块就可以创建多进程。 - 本地扩展:C或C++编写的Python扩展可以在C级别的代码中释放 GIL。这使得扩展可以在多线程中并行执行,从而绕过GIL的限制。
NumPy和SciPy等科学计算库就利用了这个特性。 - Jython和IronPython:这些 Python 的替代实现没有GIL,因此它们的多线程代码可以在多核处理器上并行执行。然而,由于各种原因,它们的使用并不广泛。
下面,我们将更详细地讨论利用多线程、多进程和协程处理并发任务的不同策略。
利用多线程处理并发任务
在Python中,多线程主要适用于 I/O 密集型任务,例如网络 I/O 或磁盘 I/O 。在这些任务中,线程大部分时间都在等待 I/O 操作完成,而不是执行计算任务。在等待 I/O 操作的过程中,线程会释放GIL,因此其他线程可以运行。
以下是一个简单的例子,展示了如何使用threading模块处理并发任务:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
import threading
import requests
import time
def download_site(url):
response = requests.get(url)
content_length = len(response.content)
print(f"Downloaded {url} with length {content_length}")
start_time = time.time()
urls = ["https://godev.me"] * 100
threads = []
for url in urls:
thread = threading.Thread(target=download_site, args=(url,))
thread.start()
threads.append(thread)
for thread in threads:
thread.join()
end_time = time.time()
print(f"Downloaded {len(urls)} in {end_time - start_time} seconds")
这个示例中,我们创建了多个线程并发下载多个网页。尽管存在 GIL ,但由于这个任务是 I/O 密集型的,所以多线程可以显著提高程序的性能。
然而,需要注意的是,多线程并不适用于 CPU 密集型任务,因为 GIL 会阻止线程的并行执行。此外,线程的创建和销毁也需要时间和资源,因此如果需要处理的任务数量非常大,或者每个任务的执行时间非常短,那么线程的开销可能会成为问题。
利用多进程处理并发任务
对于CPU密集型任务,一种常见的解决方案是使用多进程而不是多线程。每个Python进程都有自己的Python解释器和GIL,因此它们可以在多核处理器上并行执行。
以下是一个使用 multiprocessing 模块的例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
import multiprocessing
import time
def cpu_bound_task(n):
# CPU密集型任务
count = 0
for i in range(n):
count += i
return count
if __name__ == '__main__':
start_time = time.time()
pool = multiprocessing.Pool()
results = pool.map(cpu_bound_task, [10**8] * multiprocessing.cpu_count())
pool.close()
pool.join()
end_time = time.time()
print(f"Execution time: {end_time - start_time} seconds")
这个示例中,我们创建了一个进程池,并并发执行多个 CPU 密集型任务。由于每个进程有自己的GIL,所以它们可以在多核处理器上并行执行,从而充分利用多核性能。
然而,多进程也有其缺点。首先,进程的创建和销毁需要比线程更多的时间和资源。其次,进程之间的通信比线程之间的通信更复杂,需要使用进程安全的数据结构或者 序列化/反序列化 数据。
利用协程处理并发任务
协程(Coroutine)是一种可以在任意位置暂停和恢复的函数。在Python中,协程是一种非常轻量级的“线程”,它们不是由操作系统管理,而是由 Python 程序管理。协程特别适合于 I/O 密集型任务,因为它们可以在等待 I/O 操作的过程中切换到其他协程。
以下是一个使用 asyncio 模块的例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
import asyncio
import aiohttp
import time
async def download_site(session, url):
async with session.get(url) as response:
content_length = len(await response.text())
print(f"Downloaded {url} with length {content_length}")
async def download_all_sites(urls):
async with aiohttp.ClientSession() as session:
tasks = []
for url in urls:
task = download_site(session, url)
tasks.append(task)
await asyncio.gather(*tasks)
start_time = time.time()
urls = ["https://godev.me"] * 100
asyncio.run(download_all_sites(urls))
end_time = time.time()
print(f"Downloaded {len(urls)} in {end_time - start_time} seconds")
这个示例中,我们创建了多个协程并发下载多个网页。协程的优点在于它们的开销非常小,因此可以创建大量的协程。此外,asyncio 和 aiohttp 等库提供了对异步 I/O 的原生支持,使得编写异步代码变得更加简单。
然而,协程的缺点在于它们只适用于 I/O 密集型任务,而不适用于CPU密集型任务。此外,协程需要使用特殊的语法(例如 async 和 await 关键字),并且必须由一个事件循环来调度,这可能会使得代码变得更加复杂。
结论
Python的GIL限制了多线程的并行执行,但我们可以通过多进程、本地扩展或替代实现来绕过这个问题。在选择处理并发任务的策略时,需要考虑任务的性质(CPU密集型还是 I/O 密集型)、任务的数量、任务的执行时间,以及线程和进程的开销。
虽然GIL带来了一些挑战,但通过合理的策略和设计,我们仍然可以编写出高性能的 Python 并发程序。
希望这篇文章能帮助你理解 Python 的 GIL 以及如何处理 Python 并发编程的挑战。如果你有任何问题或建议,欢迎在评论区提出。